

The only real answer? Don’t have one.
Code is a great leveler. No matter how smart you are, getting your ideas to code will drag your creativity down. A diligent but otherwise unimaginative programmer likely has the same impact on a production codebase as someone capable of reliably outperforming the state of the art in a given problem space.
And listen, I'm not denying here that there are differences in people's raw coding abilities, and I'm not saying that invention is per se a desirable thing — most of the time you don't really need novel ideas; novelty for novelty's sake is as bad a sin as premature generalization, complexity, or any of the other programmer's sins.
But when novelty is appropriate, when invention is required, code often gets in the way — especially the bigger and more successful your codebase is. Code tends to calcify, to harden.
It becomes a variant of the innovator's dilemma, where new ideas become easier for new players to explore — not because of monetary reasons (as in the O.G. dilemma), but because new code is much more malleable than existing code — especially existing and successful code, i.e., deployed in products with lots of users.
The transition between the two states — malleable and hardened — is also tricky to navigate. At the beginning, you have a small team — maybe just a single person — and malleability in the architecture is not a concern. What architecture? You probably have an idea and a few lines of code — and you're trying to understand if the idea has any legs. You don't want — and should not — waste time on problems you don't have.
Then, if you're lucky, you become successful. And if you do, you can't stop; you will start feeling the pressure of the "production monster" — your users want more and more, you need to focus on features, hire more people, write even more features, rinse and repeat. Software can grow exponentially; if you're caught in an exponential, it is hard to stop the press and focus on rearchitecting code to fit your growth. You don't want — and should not — take time away from making the product bigger and better. You might be starting to slow down, but it's a problem you can throw people at.
Of course, throwing people at the problem only makes it worse faster, as now you have more engineers writing features and thus more code built on foundations that were never meant to sustain all that weight.
People do stuff. Even the laziest still do some stuff. If the stuff that gets done is not what's needed, more people only create more problems.
This is "the tyranny of code".
I don't know if it's a "law" with an existing name — but the bottom line is that if everything goes well, there's never a good time to avoid code calcification.
You are either forced once things get so slow that people who want to innovate start leaving, or you force a rearchitecture by taking the financial hit that comes from distracting resources from strictly adding more "stuff."
 "Energy flows where attention goes."
"Energy flows where attention goes."You might also observe an interesting "channeling" phenomenon — where more innovation happens in small channels, paths of least resistance that exist within the packed granular matter of code.
For example, in computer graphics, this typically happens in shader-land. As GPU shaders by their nature can't grow too big and have a very well-defined, small, simple interface with the rest of the world, they typically maintain their malleability almost indefinitely. You can live-code them, and even if you need to plumb something into the engine to provide more inputs or more passes and so on, even in the worst cases, it's still often the least painful kind of change you can make.
Again, this can be a terrible thing. People tend to want to avoid pain. If the paths of least pain are not aligned with what the code/company/product needs the most, people will keep building more in directions that are not the most beneficial — or worse, actively harmful.
Lastly, even when people don't operate out of pain avoidance, there is simply the fact that if certain things are easier, it's easier to be successful within them. How many teams that deliver innovation, outperforming the impact of their peers, do so because they happen — even unbeknownst to them — to operate on parts of the product that are less impacted by legacy?
This tends to make code grow at its periphery, only outwards into new product lands, while improvements to core functionality are ignored. And yet again, there are compounding effects, where often this new code becomes a new dependency on the core, or extends poorly designed tendrils into it — slowing things down further.
How to avoid this gloomy scenario?
We need a "two-pizza" rule for code. Bezos got it right — teams should never be large; it's simply not something we — as humans — are optimized to perform in. But it's not enough to make a team small — code should follow too. It should never be allowed to grow too large.
 Of course you want to make sure it's good, Neapolitan pizza.
Of course you want to make sure it's good, Neapolitan pizza.This means modules, of course, but modules are usually misunderstood and misused. Unfortunately, in modern computer engineering, we have a ton of ways to temporarily hide complexity — "abstract" it — probably the most dangerous word in the programmer's dictionary: abstraction.
We need to look at the active surface of code — all the code that we might realistically need to ever change or know about — and that active surface must always be limited. Creating a module that links a million others, i.e., dependencies, does not help.
True abstraction means that if something changes in an "abstracted" part of the code, I won't notice it. When a GPU vendor changes their driver code, or an OS changes its code, in the vast majority of cases I don't notice — something has to go very wrong for that abstraction to leak. And in the vast majority of cases, in my day-to-day work, I never have to know about that code. I don't need the sources. I don't want to see them.
That is not how most "modular" codebases typically work, Unfortunately! In fact, I'd wager that most ways of managing complexity we've invented over the years are actively damaging — because they don't lower the cognitive load; they don't make components truly independent from each other. Instead, they are mostly tools to manage more code — to make creating more code a bit less painful.
Build systems, distributed compilation, caches, "state-of-the-art" Git workflows, package managers, even most programming languages out there — they all focus on the wrong thing. They are all ways to make creating larger codebases easier - with no regard to their structure.
This is equivalent to trying to solve architectural problems by throwing people at them — as said before — it only kicks the problem down the line while making it bigger. In fact, the two things often compound! More people thrown at a large codebase often require "smarter" tooling, and the ball starts rolling downhill from there.
Unix got it right. KISS and small programs that can be piped together, with small, flexible interfaces between them, loose coupling. One can argue microservices are also an attempt at the same idea in the cloud-computing age. In fact, it's often said that microservices are not a solution to a technical problem, but to an organizational one.
Unfortunately, even these solutions can go wrong, because they do not enforce a strict limit on the code itself, statically. You can create a hundred services and have them all depend on hundreds of shared libraries, and presto, you've only made things more complex — saved nothing but paid a price for it.
Metrics.
If I was a business consultant and had to make a catchy (but completely unscientific) graphic, I'd say this:
1) Difficulty is mostly about people, not domains or other intristic charactersistics of the problem. In particular, technical difficulty* scales with people * lines of code, product difficulty scales with users * years of support.
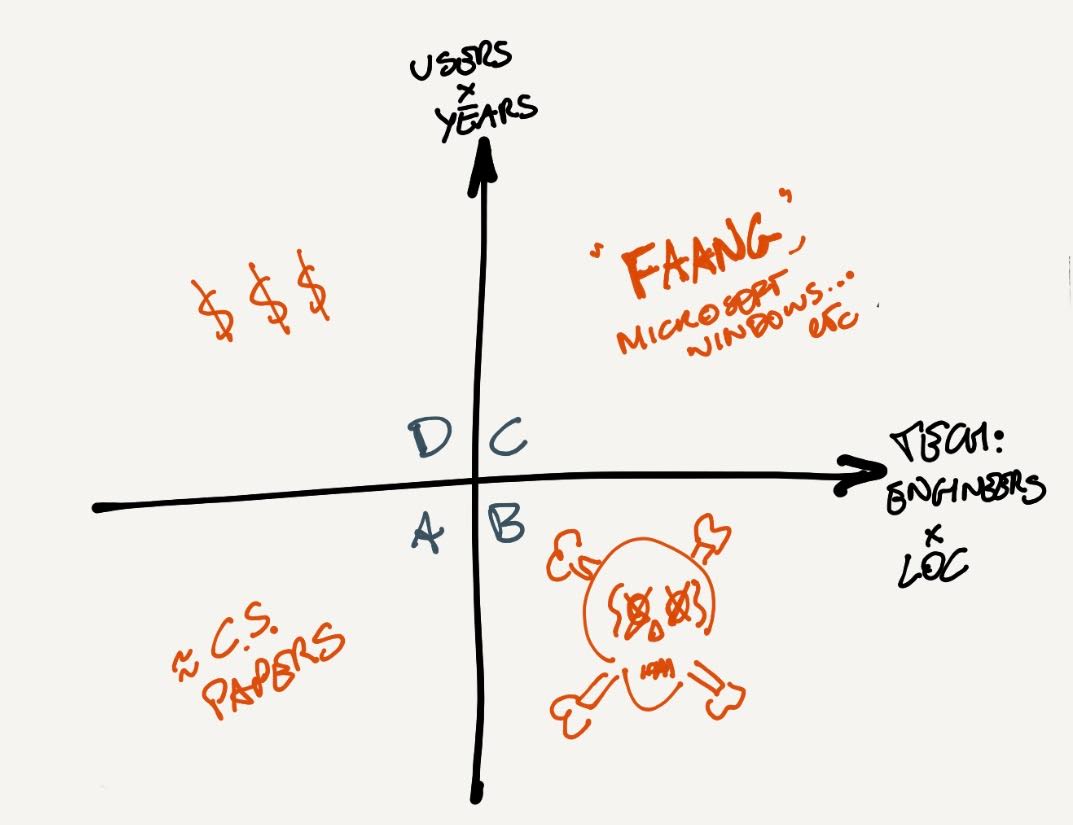 Something like this...
Something like this...Then you have four quadrants:
A - Small codebases with few users. This is the realm of experiments, prototypes, computer science papers and so on**. There can be great innovation, clean code, and occasionally delusions of grandeur. Sometimes people in this camp think they are absolute geniuses because they coded something that greatly outperforms successful, well-known solutions. In practice, this is relatively speaking - trivial, it's the "easymode" of programming.
B - Large codebases/companies with few users. A.k.a. dead. This is what we want to avoid. Maybe once upon a time, you were in C, and fell down here...
C - Large codebases at large companies with lots of users and legacy. Windows, Google et al. You made it! You are playing in hardmode and surviving the production monsters. You are (part of) a trillion dollar corporation. Congrats!
D - Small codebases with lots of users and legacy. You're a billionare and a celebrity coder. What are you doing here? Well, if I have your attention, a word - beware not to develop in the same fallacy that can affect people in A. You are successful, you definitely did things right, but you did not face the hardmode monster.
notes:
* Not that there is no genius in algorithms and programming - there is, and the perils of too much code can frustrate it. What I'm saying though that it is much harder, even intellectually as an engineer, to do great code at scale, than to do it with no users.
** Quadrant A is is also the realm of the current trend of "xyz rewritten in Rust is so much faster" - people don't grok that the "rewritten" part is what made the difference, not the "Rust" part.
2) Modern development tools are often actively damaging.
 All-to-all dependencies are hell.
All-to-all dependencies are hell.At least... the ones we commonly use and even ask for. It has been long understood in computer engineering that abstraction, modularity and reuse per-se do not mean much. We even have some tools and metrics to measure aspects of architecture quality - for example the "dependency structure matrix", "code coverage" etc.
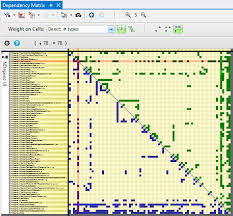 NDepend.
NDepend.It has also been long known most real-world graphs tend to have cliques, small sets of strongly-connected nodes. It's arguable that these, in computer science, represent opportunities or instances where the modularization is not yielding benefits, and merging of the nodes should be considered...
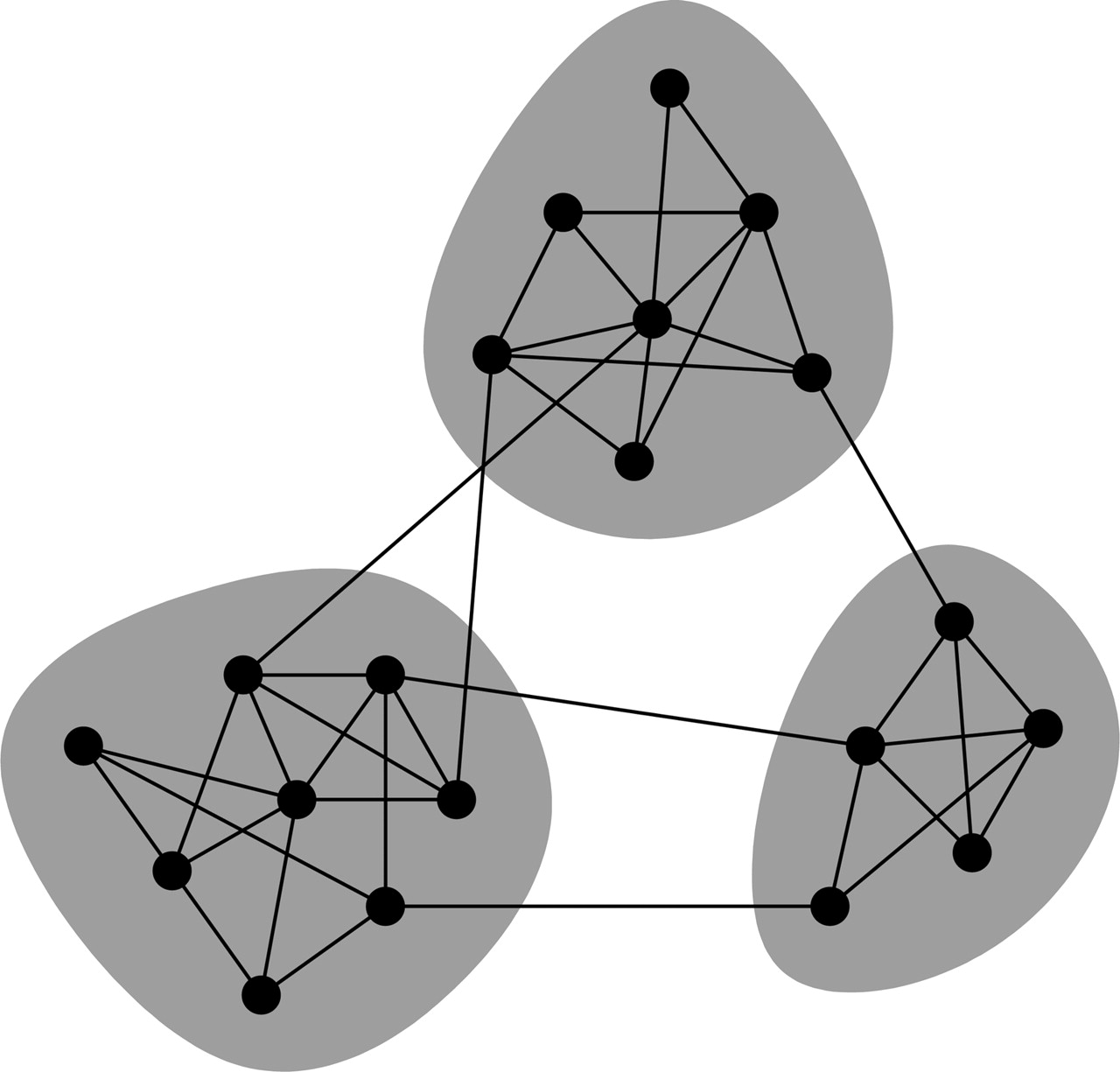
But unfortunately, these are not the tools and metrics that most often drive the codebase.
In part this happens because they are not that useful in practice - they measure only specifics that don't really tell much about the code overall. Static dependencies (includes, packages etc) don't reflect the runtime nature of the code, they can't give a sense of the "strenght" of the coupling, of the size/complexity of the interfaces. They are at best partial proxies for the real question: how much any change affects anything else outside it - either directly (code that needs to be modified), in runtime (behavioral changes that "leak" outside the domain of the change) and on the human level (how many people need to know/will be affected).
But this is not the main reason - where there's a will, there's a way... The main problem is one of short-sightedness - it is the focus on adding stuff, and adopting tooling that facilitates "more".
Conclusions.
In the end, fighting code calcification is not a tooling problem, it’s a cultural one. Code is easy to write. It's much harder to stop writing it. Don't hide code, stare at it. In fear.
P.S. Originally, I wanted to write this as a small note in an article on the (positive) value of pain and friction — but as always, I write too much, so that now has to wait for another time.